Hallo. Schön, dass du da bist.
Die hier gehosteten Digilabs stehen als standalone-fähige Quellcodepakete über die jeweiligen Bitbucket-Links zur Verfügung und können frei geklont, geteilt, bearbeitet, verwendet, gegessen, präsentiert, neu entworfen, bestaunt und/oder sonstwie be- um- an- hoch- und runtergezogen werden.
Falls du etwas hilfreiches finden konntest oder einfach gerne individuelle Open Data Initiativen förderst, findest du hier Möglichkeiten dazu.
Statistik
Hier entsteht ein Digilab für allgemeine statistische Analysen. Die Theorie folgt einer Statistikvorlesung auf Basis von Andy Fields Lehrbuch. Die natürlich vollkommen fehlerfrei ausgearbeitete Vorlesung entstand an der Abteilung für Computational Humanities der Uni Leipzig und steht in Form von Folien und Videos zur Verfügung.
Damit soll ein Gesamtpaket erstellt werden, welches eine autodidaktische Statistikausbildung ermöglicht und grundlegende statistische Verfahren niedrigschwellig zur Verfügung stellt.
Text Service Infrastruktur


Durch die Inklusion der Distributed Text Service Spezifikationen wurde der Fokus der Canonical Text Service Infrastruktur auf eine allgemeinere Text Service Infrastruktur erweitert. Darin enthalten sind Möglichkeiten der API-Abfrage sowohl von allgemein gehaltenen textanalytischen Funktionen als auch die etablierten Modelle Canonical Text Service (CTS) und Distributed Text Service (DTS). Als Daten steht eine eine wachsende Anzahl an Textkorpora zur Verfügung, die bereits eine über 300 millionen Worte starke digitale Bibliothek bilden.
Außerdem stehen diverse Möglichkeiten des Text Minings, Exporte für Sprachmodelle und Vertikalisierte Korpora sowie nutzerfreundliche Tools zur Datenxploration zur Verfügung, die – zusammen mit den Abfragemöglichkeiten der Text APIs selbst über GET, Python oder Javascript – eine interoperable und RESTful funktionierende Infrastruktur für textbasierte Forschungsdaten bilden, welche das Ideal des aktuellen Forschungsdatenmanagements (FDM) umzusetzen versucht.
Niedersorbisches Text Mining
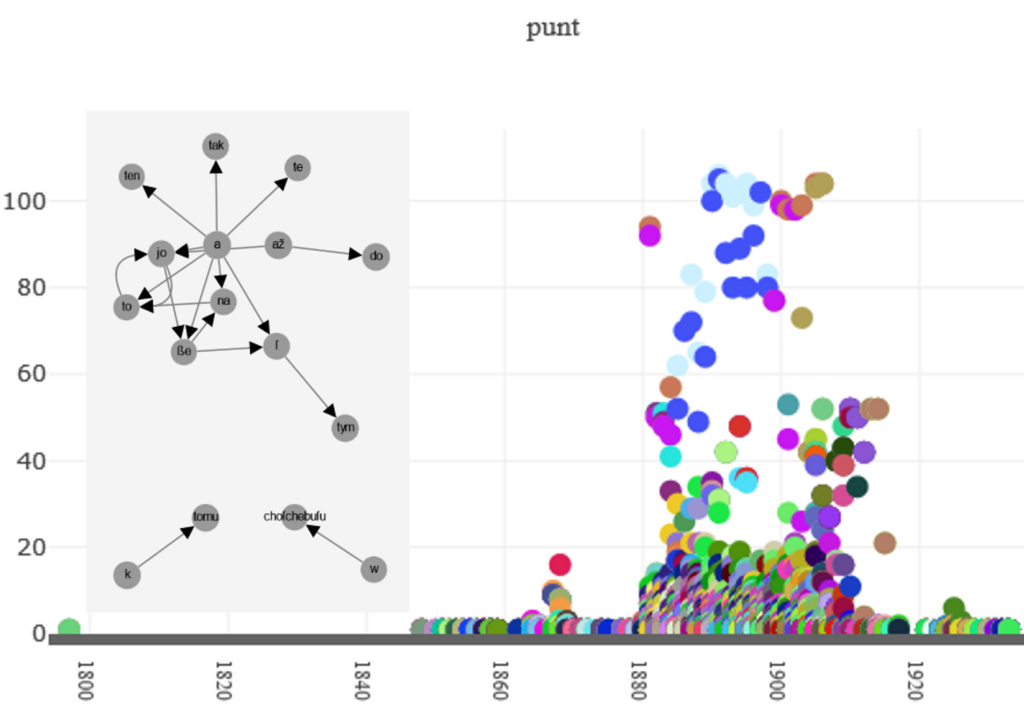
Der niedersorbische Textkorpus des Sorbischen Instituts (Niederlassung Cottbus) spiegelt das gesamte verschriftliche Wissen über die niedersorbische Sprache wider und formt damit ein wunderbar praktisches Fallbeispiel für den Ausbau der korpusanalytischen Säule der Text Service Infrastrktur.
Im Laufe der Arbeit werden diverse Korpusanalysen generisch implementiert und in einem Digilab gesammelt.
Parallel Text Alignment
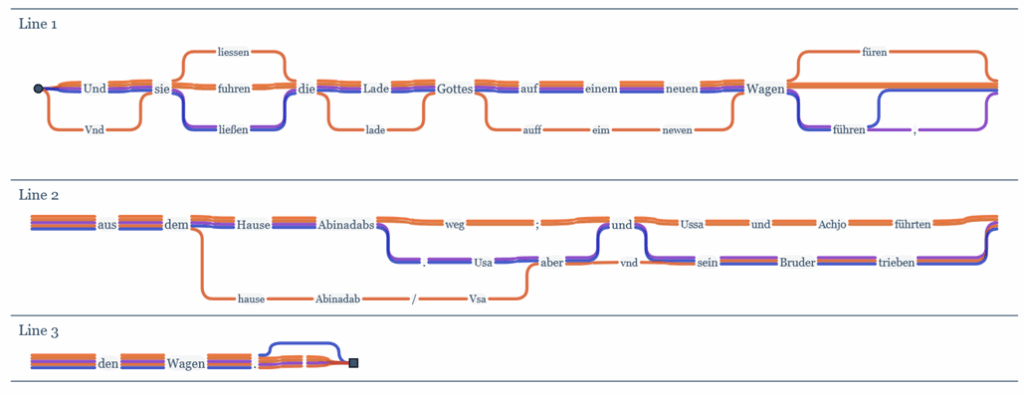
Dieses Tool erlaubt es, Variationen von Dokumenten in verschiedenen Übersetzungen einer Sprache durch Alignment zu visualisieren.
Je nachdem, wie einheitlich Editionen strukturiert sind, lässt sich die Strukturinformation sehr elegant zum Alignment nutzen. Bibeltexte sind dafür perfekt geeignet, weshalb Editionen des Parallel Bible Corpus als Versuchsgegenstand genutzt werden. Visualisiert wird das Alignment via Stefan Jaenickes TRAViz Bibliothek.
Es stehen 5 deutsche (elberfelder1871, elberfelder1905, luther1545, luther1545letztehand, luther1912), 3 französische (davidmartin, kingjames, louissegond) sowie 2 englische (darby, kingjames) Bibelübersetzungen zur Verfügung, die jeweils innerhalb der Sprache aligniert werden.
Die Georeferenzierungs-werkzeugsammlung
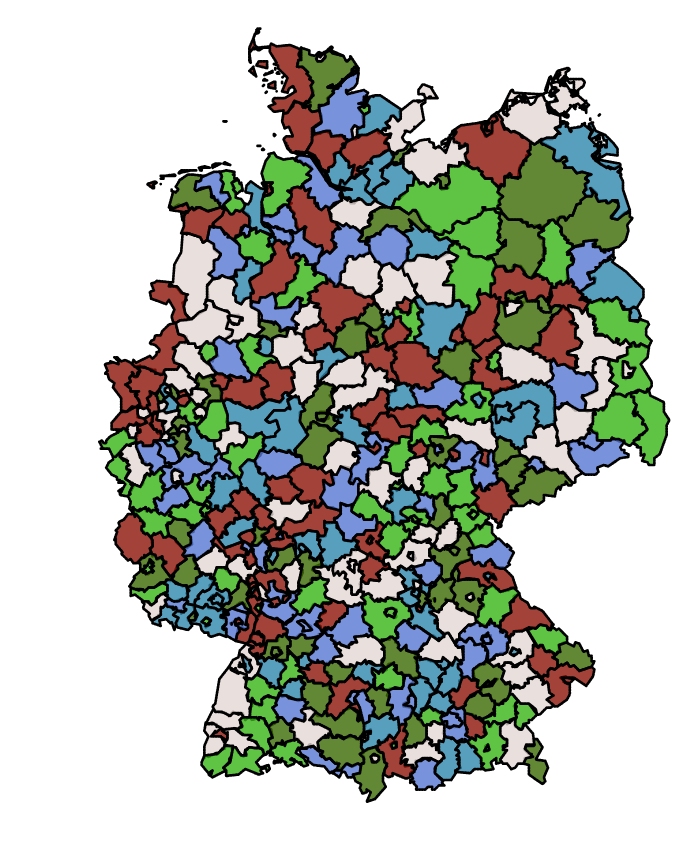
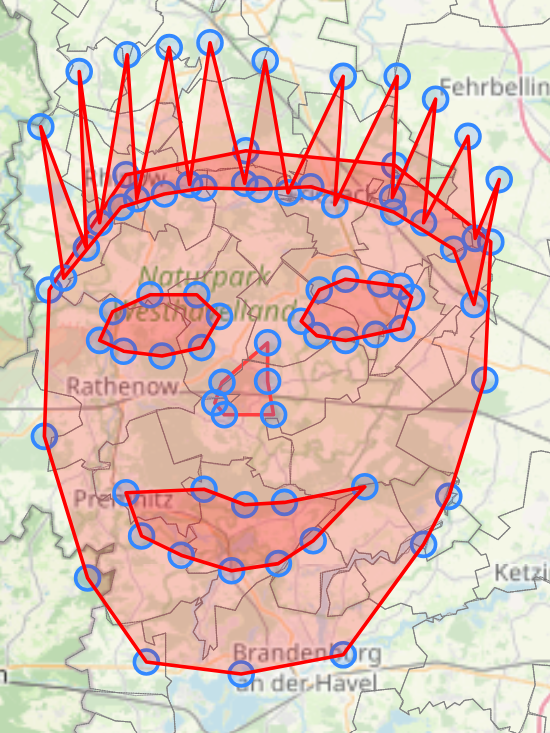
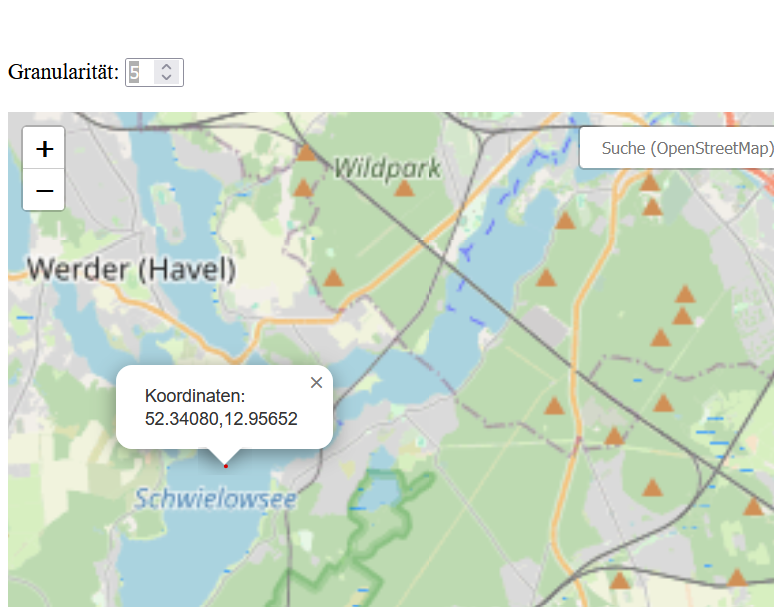
Es ist unangenehm, dass man bei Georeferenzierung viele Klicks für einfache Arbeiten benötigt, dabei am besten noch Popups wegklicken und herumscrollen muss und durch die Werkzeugnutzung von Firmen wie Microsoft und Google die eigenen Forschungsdaten in irgendwelchen immer cloudbasierter werdenden Prozessen gesammelt werden.
Hier entstehen rein clientseitig arbeitende OpenSource Werkzeuge, die auf georeferenziertes Forschungshandwerk ausgerichtet sind. Aktuell gibt es Tools für Koordinatenrecherche & Polygonerstellung per Klick, Kartenpins & Chloroplethkarten per Zahleneingabe und Datenabfrage zur Registerdatenbank des Sorbischen Instituts.
Verfügbare Kartenlayer beinhalten globale und – für Deutschland – regionale Karten verschiedener Granularitätsebenen sowie historische Weltkarten von BC 123000 bis AD 2010.
Es wird nichts geloggt und alles passiert im persönlichen Browser. Die Kartenlayer und Ortsuche werden von OSM abgefragt. Der Quellcode ist in sich geschlossen und kann selbst gehostet werden.
Proof of Concept: Bilddatenzertifizierung

In Zeiten von KI generierten Fake News und/oder manipulierten Fotos wird es zunehmend wichtig, Bilder zu zertifizieren. Dieser Ansatz versucht dies umzusetzen, indem die Pixelfolge des Bildes clientseitig eingelesen und per POST Request and den Server geschickt wird. Dort wird diese Pixelfolge anschließend als MD5 Hash gespeichert.
Durch diese Trennung erübrigen sich Datenschutzproblematiken und Sicherheitsrisiken, die durch den Upload des Bildes auf einen Server entstehen würden. Andererseits führt die Unumkehrbarkeit von MD5 Hashes dazu, dass pixelgenaue Änderungen des Bildes eine Änderung der Bildsignatur erzeugen. Das Verwenden von POST verhindert, dass die Pixelinformationen in irgendwelchen Log-Dateien gespeichert werden.
Die genaue Hashfunktion kann serverseitig angepasst werden, entweder über ein entsprechenden Salt oder durch die Verwendung anderer Algorithmen. Trotz Open Source Ansatz kann die Erzeugung der Signatur also geheim bleiben und es lassen sich Bilder datenschutzkonform und sicher pixelgenau zertifizieren.
In der Entwicklungsdemo ist der Signierprozess frei zugänglich, aber sollte im Produktivbetrieb natürlich serverseitig mit einem Passwort geschützt werden.
Graphdaten / Netzwerkanalysen
Hier wird zeitnah ein Digilab entstehen, welches verschiedene Analysen bezüglich Graphdaten ermöglicht. Dabei sollen sowohl generische Analysen (Ranking, Clustering, …) bereitgestellt werden als auch thematisch spezialisierte Analysen wie Drama Mining über Konfigurationsmatrizzen und diachrone semantische Netzwerkanalysen mittels Semporalgraphen.
Angestrebt wird eine Verknüpfung des Semporalgraphen mit der Georeferenzierungswerkzeugsammlung um auf diese Art Wissen über Raum und Zeit in einem semantischen Netzwerk explorierbar zu machen.
Eventuell wird das Thema Reasoning über Dung’s Argumentation Frameworks ebenfalls eingebunden, das könnte im praxisnahen Kontext ziemlich spannend werden.
Definitiv spannend werden Text-Reuse Netzwerke (Zitatgraphen) in diesem Kontext.
Proof of Concept: IWS Corpus Workbench Viewer
Die Installation und Anwendung von CQPWeb erweist sich als sehr umständlich und schlecht dokumentiert. Aus diesem Grund wird hier ein Viewer für bestehende Datensätze entstehen, der CWB Anfragen und passende Visualisierungen für auf dem Server installierte CWB Textkorpora in eine einfache Online-GUI wrappt. Die Daten müssen vorher mittels cwb-encode aufbereitet und indexiert werden.
{kind=link}
WhataboutHanna
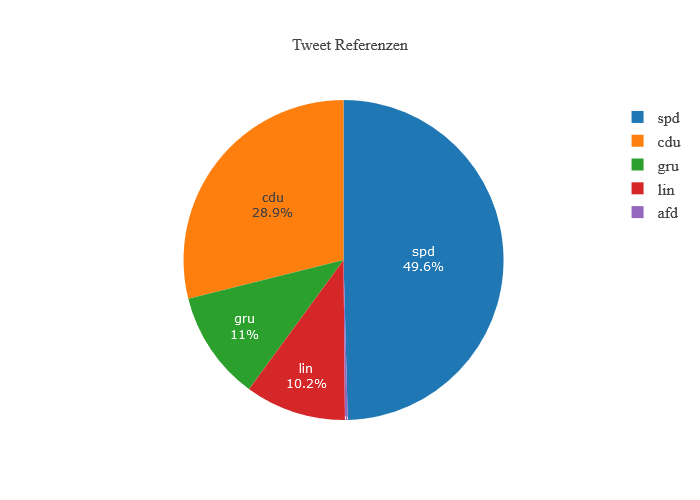
Bevor Twitter zu X (ehemals Twitter) mutierte, existierte eine Abfrageschnittstelle, über die Twitterdaten zu Forschungszwecken gecrawlt werden konnten. Diese Schnittstelle wurde genutzt, um die Diskussion zum Thema prekärer Arbeitsverhältnisse im Wissenschaftsbetrieb quantitativ zu analysieren. Tweets zu den Hashtags #ichBinHanna #ichBinReyan, #wisszeitvg und #dauerstellen wurden gecrawlt und darauf aufbauende Analysen in diesem Digilab datenschutzkonform aufbereitet und bereitgestellt.
Aufgrund der „moderneren“ Ausrichtung von X (ehemals aber umgangssprachlich immernoch und irgendwie wohl für immer Twitter) wird es wohl eine der aktuellsten und einzigen frei zugänglichen quantitativen Twitteranalysen bleiben.
MDR Corona Ticker Text Mining

Während der Coronapandemie entstand ein hoher Bedarf an schnell vermittelten Nachrichten. Dabei wurden von diversen öffentlich-rechtlichen Nachrichtenseiten Coronaticker geführt. Diese Coronaticker bilden rückblickend ein sehr feingranulares Archiv von Geschehnissen ab und sind damit eine nicht zu unterschätzende Wissensquelle über die Pandemie für die Nachwelt.
Dieses Digilab enthält Text Mining Analysen sowie die Nachrichteninhalte zum MDR Coronaticker – eine Forschungsarbeit, die am Hannah-Arendt-Institut für Totalitarismusforschung (Dresden) entstanden ist. Bilddaten wurden dabei aus Urheberrechtsgründen nicht inkludiert.